
SUMMARY
We have used Natural Language Processing (NLP) techniques in tools aimed to support and improve the software development and software quality processes for Java and C/C++ languages.
The use of complex models has increased performance in many common NLP tasks, such as named entity recognition, text classification, summarisation and translation among others. Besides, transfer learning has also become an interesting option when not much labelled data is available and knowledge learnt from one problem can be applied to a new but related task. In this context, our two NLP-based source code analysis tools - namely Variable Misuse and Code Summarisation - have been conceived by and for software developers:
Variable Misuse tool
Finding bugs is a core problem in software engineering and programming language research. The challenge in this domain rests not only in correctly characterising source code that contains a bug with high precision and recall, but also in being able to automatically correct it – in the figure below, the variable password in red on the left should be detected as a defect and replaced with the variable username in blue on the right. This is especially difficult because of the rarity of bugs and the extreme diversity of (correct) source code. As a consequence, due to its potential to improve programmer productivity and software quality, automated program repair (APR) has been an active topic of research in recent years.

The architecture of the model we use to address the variable misuse detection and repair task in our Variable Misuse tool is based on (Vasic, Kanade, Maniatis, Bieber, & Singh, 2019) work, which allows for performing joint prediction of both the location and the repair for bugs. In essence, this model is a kind of encoder-decoder model that combines a Long Short-Term Memory (LSTM) (Hochreiter & Schmidhuber, 1997) recurrent neural network with Pointer Networks (Ptr-Net) (Vinyals, Fortunato, & Jaitly, 2015). In order to build and train the model, pre-processing and feature extraction steps are implemented. This starts with the tokenisation of the source code file to represent methods as token sequences, where each token has an associated type. Then, the sequences are filtered by length and mapped to a numerical representation for the construction of a vocabulary, which includes an unknown (<UNK>) token for words not present when making predictions over new datasets. Finally, sequences with a number of tokens below a threshold are padded.
Models for Java and C/C++ languages achieve both very good performances for the classification task. In particular, the model implemented for those programs written in Java is able to classify correctly around 94% of the files as fault or correct, while this value is 93% in case of the C/C++ programs. Moreover, the models also present high precision when it comes to predict the exact localisation of the bug within a source code file. For buggy programs, these accuracies are 86% and 84% for the Java and the C/C++ use cases, respectively. However, there are some differences in the bug-repair capability of both models. The Java model outperforms the model implemented for C/C++ use case, since it is able to correctly locate and repair the bug for a roughly 70% of the buggy Java programs, whereas the C/C++ model manages to repair a 59% of them.
Code Summarisation tool
Although Code Summarisation is a relatively new research area, there are already studies focusing on different representational methods and modelling techniques. In (Hlib Babii, 2019), the authors gather information, techniques and studies related to the modelling of vocabulary for Big Code applications. They widely present possible solutions for the pre-processing of both source code and the natural language artifacts, such as comments and literals contained within. Our code summarisation tool processes source code in Java and C/C++ languages producing as output a brief description of the aim of each method/function, and this is inserted before the definition following documentation standards.
The architecture (see figure below) in our Code Summarisation tool implements an encoder-decoder neural network, with an additional attention layer, which is widely used in developing deep learning language models used in machine translation, text summarisation, image captioning, etc. On the one hand, this kind of network is composed of an encoder, which processes the input sequence and returns its own internal state, which will serve as the "context" of the decoder. On the other hand, by disposing of such information, the decoder learns to use the ground truth from a prior time step as input in order to generate targets [t+1...] given targets [...t], conditioned on the input sequence in a process called "teacher forcing".
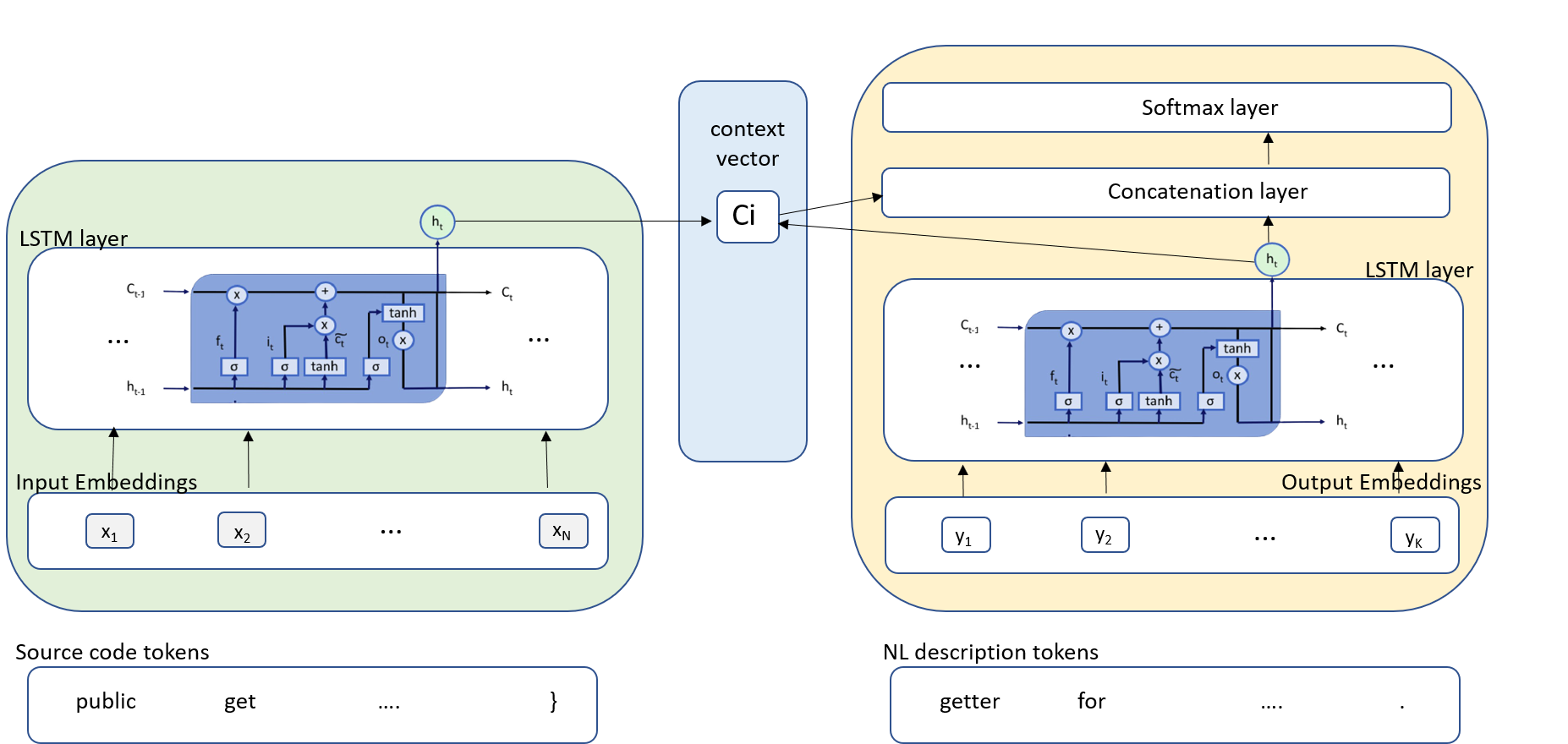
The pre-processing phase for building the model consists of several steps to adapt the raw source code to the pre-defined input data. Firstly, functions are identified based on word tokenisation to clearly define the snippet of code to analyse. Then, tabs and punctuation are discarded, and labels are assigned to any number. Following this, low frequency tokens are removed while the rest of tokens are converted into lowercase.
The developed summarisation models already deliver good results, based on the selection metric adopted, even though the Java model outperforms the C/C++ model, supported by the availability of more training labelled data. In particular, the Java models reaches a BLEU_4 (NLTK smoothed implementation) score of 0.33 on the validation set while the C/C++ model scores 0.29. When considering the ROUGE-L scores on the same sets, results are more similar, having a score of 0.50 for the Java model and 0.49 for the C/C++ model.
The model predictions can sometimes reflect the true functionality of the input methods, especially if their natural language descriptions are concise enough. However, a positive behaviour for the models is generally observed even when the metrics are not able to reflect it. In most cases, the structure of the generated sentence is well organised and semantically correct. Moreover, predicted summaries often start with verbs/nouns according to their original summaries and sometimes synonyms are well interchanged.
REFERENCES
(Hlib Babii, 2019) Hlib Babii, A. J. (2019). Modeling Vocabulary for Big Code Machine Learning, ArXiv. Retrieved from https://arxiv.org/abs/1904.01873
(Hochreiter & Schmidhuber, 1997) Hochreiter, S., & Schmidhuber, J. (1997). Long Shor-Term Memory. Neural Computation, 9(8), 1-32. Retrieved from http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.676.4320&rep=rep1&type=pdf
(Vasic, Kanade, Maniatis, Bieber, & Singh, 2019) Vasic, M., Kanade, A., Maniatis, P., Bieber, D., & Singh, R. (2019). Neural Program Repair by jointly Learning to Localize and Repair. ICLR, (pp. 1-12). Retrieved from https://arxiv.org/pdf/1904.01720.pdf
(Vinyals, Fortunato, & Jaitly, 2015) Vinyals, O., Fortunato, M., & Jaitly, N. (2015). Pointer Networks. Advances in Neural Information Processing Systems 28 (NIPS 2015), (pp. 1-9). Retrieved from https://arxiv.org/pdf/1506.03134.pdf
ACKNOWLEDGEMENTS
These developments have been performed under the DECODER project (CORDIS page). This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 824231.

Created with Mobirise site templates